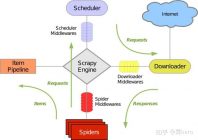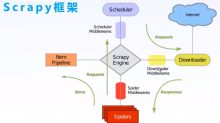
一、整体原理图
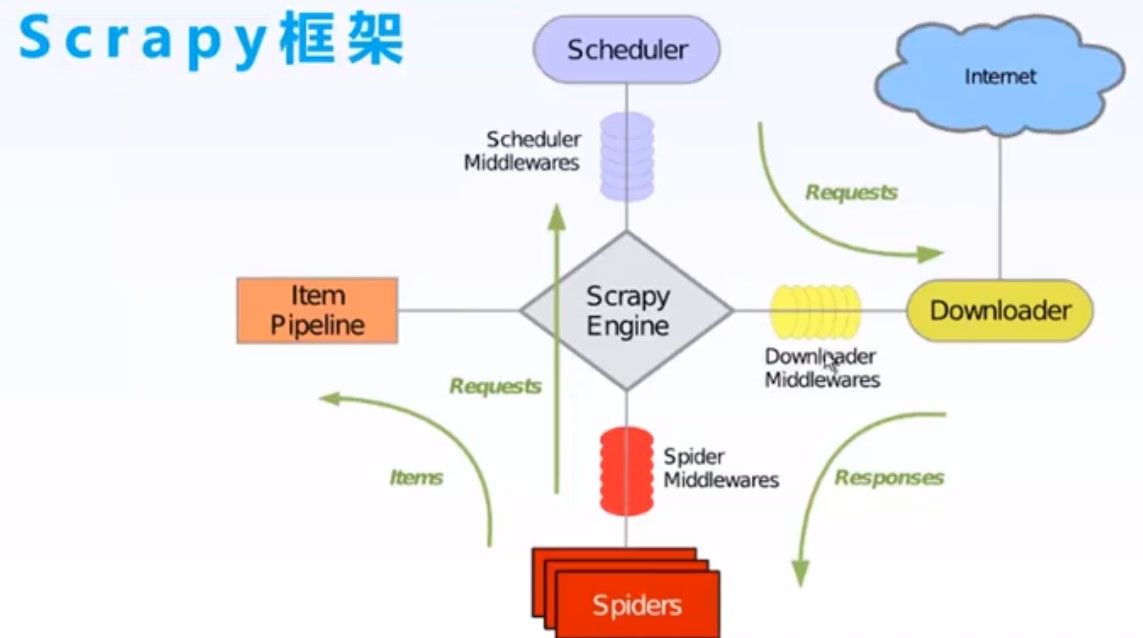
二、工作流程图
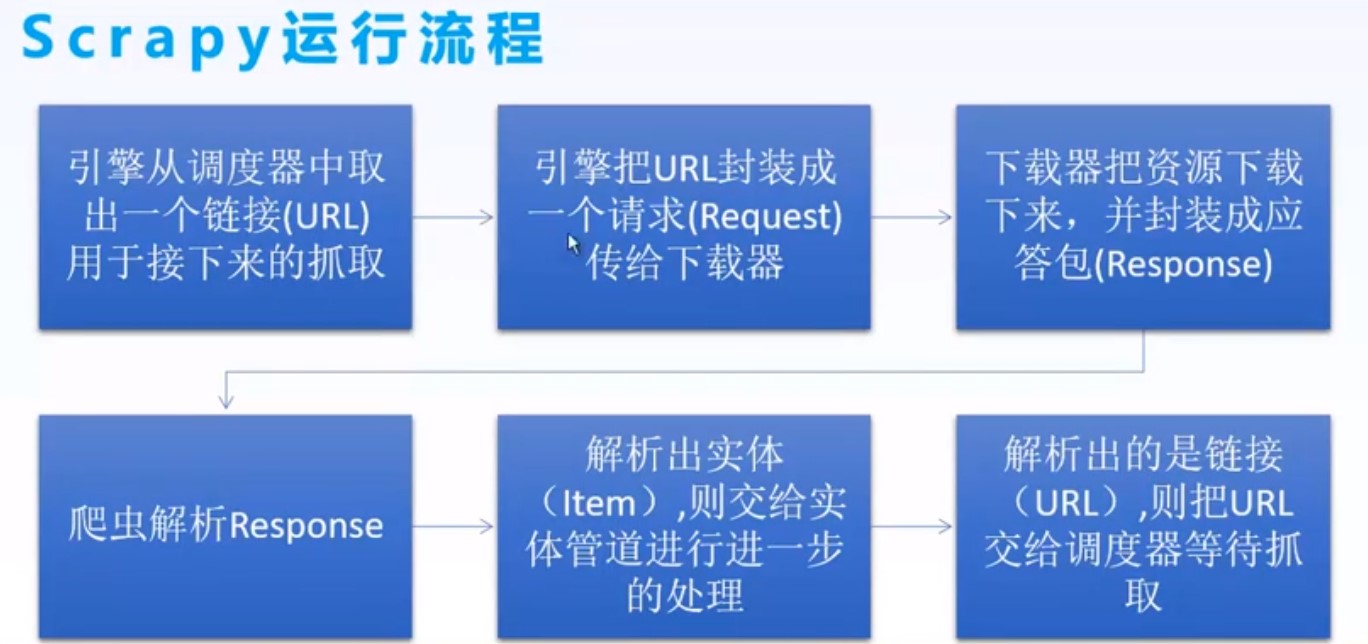
三、创建项目


四、项目架构文件简述
五、功能实现步骤
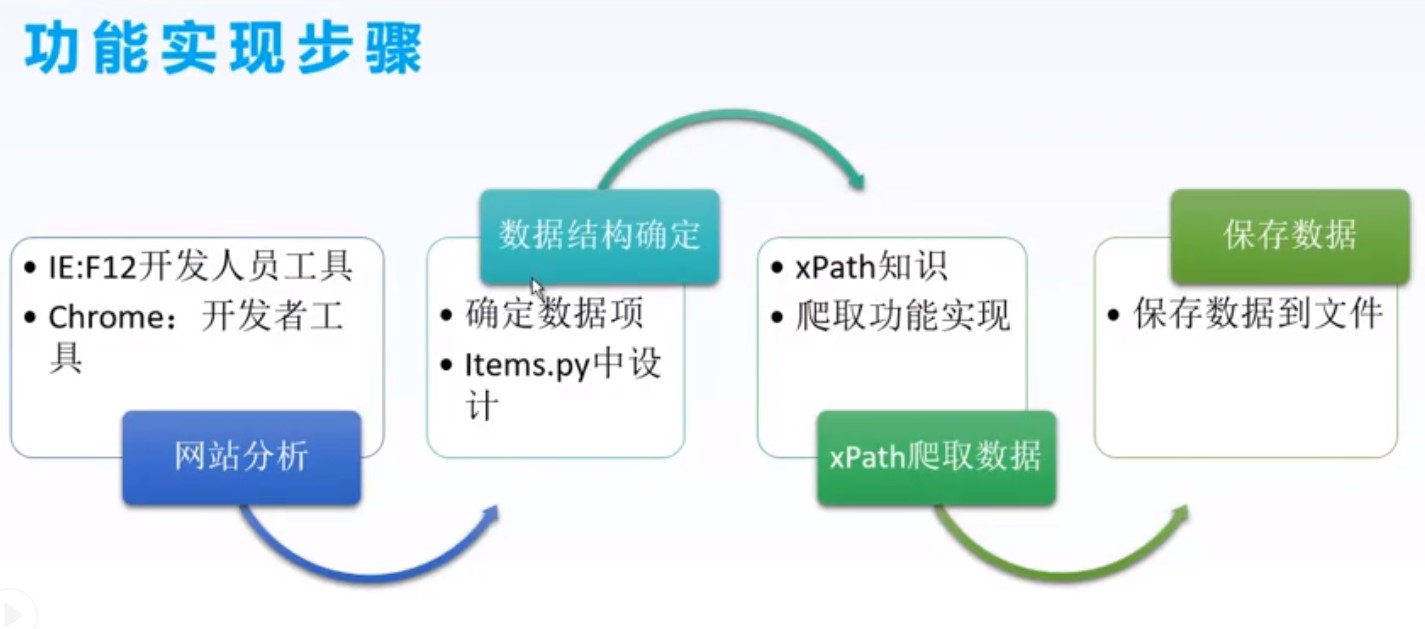
1、分析网站
chrome 打开网站,ctr+shift+i 打开开发者工具,按F5刷新网站
2、items.py (定义需要处理的数据结构)
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
director=scrapy.Field()
actor = scrapy.Field()
star = scrapy.Field()
score = scrapy.Field()
link = scrapy.Field()
class DoubanMyNotesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
content=scrapy.Field()
date = scrapy.Field()
小问题:PyCharm同目录下导入模块会报错的问题
3、moveSpider.py (在列表页中获取信息)
from scrapy.spiders import Spider
from scrapy import Request
import re
from douban.items import DoubanItem
class movieSpider(Spider):
# 爬虫名称
name = "movieSpider"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"}
# 第一次请求的url
def start_requests(self):
url = "https://movie.douban.com/top250"
yield Request(url, headers=self.header)
# 解析网站,获取信息
def parse(self, response):
item = DoubanItem()
# 获取首页全部电影信息
allFilmInfo = response.xpath("//div[@class='info']")
# 循环获取每一部电影的全部信息位置
for oneSelector in allFilmInfo:
# 电影名称
name = oneSelector.xpath("./div[1]/a/span[1]/text()").extract()[0]
director_actor = oneSelector.xpath("./div[2]/p[1]/text()").extract()[0]
director = re.findall("导演: (.*?) ", director_actor)[0] #.*?非贪心算法,整个字符串只匹配一次,匹配到空格符第一次出现停止。()表示匹配内容输出。
try:
actor = re.findall("主演: (.*?) ", director_actor)[0]
except:
actor = ''
star = oneSelector.xpath("./div[2]/div/span[2]/text()").extract()[0]
score = oneSelector.xpath("./div[2]/div/span[4]/text()").extract()[0]
score = re.findall("(.*?)人评价", score)[0]
link = oneSelector.xpath("./div[1]/a/@href").extract()[0]
item["name"] = name
item["director"] = director
item["actor"] = actor
item["star"] = star
item["score"] = score
item["link"] = link
yield item #把数据给管道文件pipelines.py进行保存处理
# 获取下一页的网址链接
nextUrl = response.xpath("//span[@class='next']/a/@href").extract() #a/@href表示获取a的属性href的值
if nextUrl:
nextUrl = "https://movie.douban.com/top250"+nextUrl[0]
yield Request(nextUrl,headers=self.header)
start.py (在pycharm中运行代码)
from scrapy import cmdline
cmdline.execute("scrapy crawl movieSpider".split())
pipelines.py (对获取到的item数据进行保存处理)
class DoubanPipeline:
def process_item(self, item, spider):
with open("movieinfo.txt","a",encoding="utf-8") as f:
oneMovieStr=item["name"]+"@"+item["director"]+"@"+item["actor"]+"@"+item["score"]+"@"+item["star"]+"@"+item["link"]+"\n"
f.write(oneMovieStr)
return item #这里的return item 把数据显示在运行屏幕上,例如pycharm的运行窗口
settings.py (把管道打开)
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# ITEM_PIPELINES = {
# 'douban.pipelines.DoubanPipeline': 300,
# }
把管道打开
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300, #300是优先级,数值越小优先级越高
}