寒假在家,实在无事可做,就找到了崔庆才爬虫52讲的课程,巩固一下爬虫知识,最近也是学到了异步爬虫,本来想按照视频教的案例实践一下就可以了,没想到案例网站证书过期了,没办法进行实践,只能去找别的网站实践了。
一开始学习爬虫就是看到别人爬取美女图片(主要是因为图片网站没有什么反爬,绝对不是冲着图片去的),就是刚开始都是一张一张下载的,速度及其的慢,既然学了异步爬虫就想着能不能异步爬取图片加速图片的爬取。
说干就干,直接百度搜索电脑壁纸,随机选取“幸运儿”。
有请我们的幸运儿:彼岸图网
分析
我们直接进入4K动漫壁纸页面,分析初始页面的url,可以看到页面的url![]()
翻页观察一下
![]()
多翻几个页面,很明显的可以总结出页面url的变化规律:http://pic.netbian.com/4kdongman/index_{page}.html
可以看到初始url还是很简单的。
接下来我们分析一下拿到图片的链接
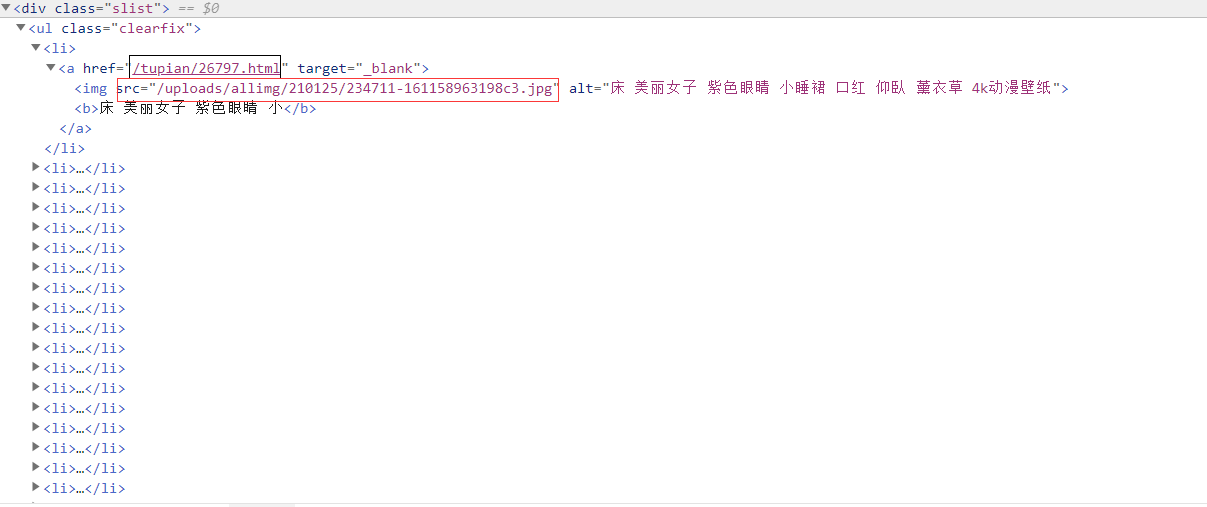
这里我先选择了直接打开scr里面图片链接,发现图片非常的模糊,而且非常的小,这肯定是不适合做我们的电脑壁纸。
继续往下分析,随便打开一个图片链接
![]()
发现刚好是初始地址加上面我们分析获得的href属性组成的。
即http://pic.netbian.com{id}.html
再分析一下源代码
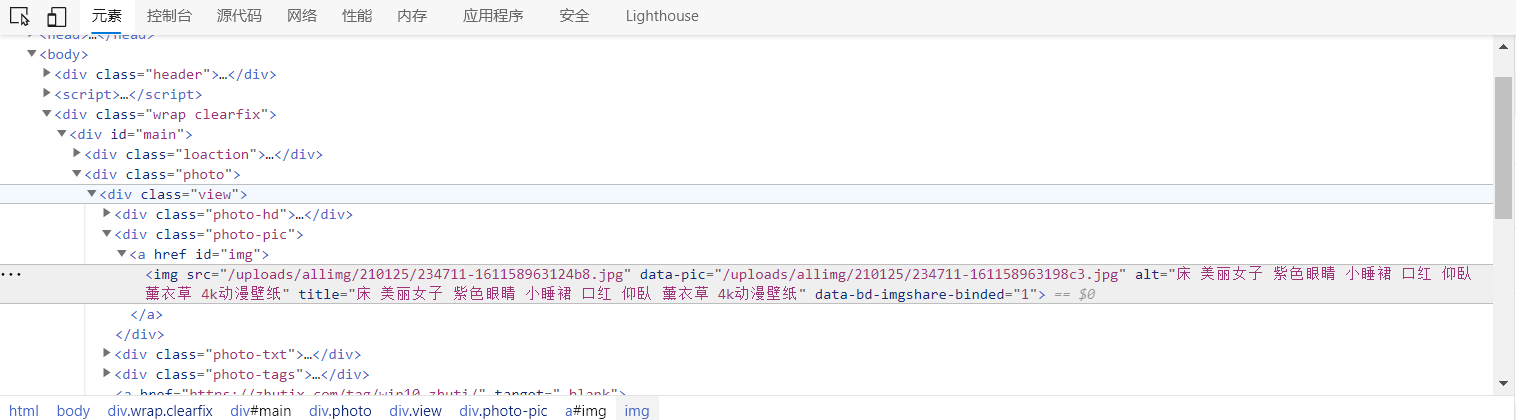
再次定位到src属性,拼接上网站的初始url,浏览器打开图片,果然是我们想要的图片地址。
接下来用代码实现就很简单了,我们首先请求初始页面,提取出详情页面的url,再请求详情页面,解析详情页面拿到图片的链接和地址就可以了。(我这里用的是re暴力匹配的,也可以用bs4,lxml等方法)
代码实现
import asyncio
import re
import aiohttp
import logging
import os
# 定义日志文件
logging.basicConfig(level=logging.INFO,format="%(asctime)s-%(levelname)s:%(message)s")
# 定义初始页的url
INDEX_URL = "http://pic.netbian.com/4kdongman/index_{page}.html"
# 定义详情页的url
DETAIL_URL = "http://pic.netbian.com{id}.html"
# 定义壁纸的初始url
IMG_URL = 'http://pic.netbian.com{img_url}'
# 定义将要爬取的页数
PAGE_NUMBER = 147
# 定义爬取的信号量
CONCURRENCY = 5
# 构造存储壁纸的路径
PATH = "D:\img"
if not os.path.exists(PATH):
os.mkdir(PATH)
# 初始化信号量
semaphore = asyncio.Semaphore(CONCURRENCY)
session = None
# 此函数的功能是定义一个基本的抓取方法,传入url即可返回网页的源代码
async def scrape_api(url):
async with semaphore:
try:
logging.info('scraping %s',url)
async with session.get(url) as response:
return await response.text()
except aiohttp.ClientError:
logging.error('error occurred while scraping %s',url,exc_info=True)
# 此函数的功能是构造初始页的url
async def scrape_index(page):
url = INDEX_URL.format(page=page)
return await scrape_api(url)
# 此函数的功能是定义详情页的url,并解析详情页,拿到img的url和名字
async def scrape_detail(id):
url = DETAIL_URL.format(id=id)
data = await scrape_api(url)
IMG = re.search('<img src="(.*?)" data-pic',data,re.S).group(1)
img_url = IMG_URL.format(img_url=IMG)
name = re.findall('<img.*?title="(.*?)"',data,re.S)[0]
return await scrape_save_img(img_url,name)
# 此函数的功能是访问图片的链接,并返回二进制数据
async def scrape_save_img(url,name):
async with semaphore:
try:
logging.info('scraping %s',url)
async with session.get(url) as response:
img = await response.read()
return await save_data(img,name)
except aiohttp.ClientError:
logging.error('error occurred while scraping %s',url,exc_info=True)
# 此函数的功能是存储图片
async def save_data(img,name):
with open(f'D:\img\\{name}.jpg',"wb") as f:
print('正在存储图片')
f.write(img)
f.close()
print('图片存储成功')
# 主函数
async def main():
global session
# 初始化session
session = aiohttp.ClientSession()
# 定义爬取列表页的所有task
scrape_index_tasks = [asyncio.ensure_future(scrape_index(page))for page in range(2,PAGE_NUMBER+1)]
# 调用asyncio.gather方法传入task列表,将结果赋值给result,这个result就是所有task返回结果的列表
result = await asyncio.gather(*scrape_index_tasks)
logging.info('result %s',result)
# 遍历result
for index_data in result:
# 判断index_data是否为空,防止出现空白index_data导致程序意外终止
if not index_data:continue
ids = re.findall('<li><a href="(.*?).html" target="_blank"><img',index_data,re.S)[1:20]
# 声明爬取所有详情页task组成的列表
scrape_index_tasks = [asyncio.ensure_future(scrape_detail(id))for id in ids]
# 调用asyncio.wait方法调用执行,也可以用gather方法,效果一样,返回结果有差异
await asyncio.wait(scrape_index_tasks)
# 关闭session
await session.close()
# 程序开始运行
if __name__ == '__main__':
# 调用异步协程
asyncio.get_event_loop().run_until_complete(main())
代码主要是仿照着教学视频上面的风格写的(感觉视频上面的代码逻辑十分清晰,就仿照这这种风格写了),注释什么的也写的很清楚,不懂的可以自己看哈。
之后我又打开了几个网站元气壁纸,观察了一下感觉这些图片网站的结构都是一样的,标签页,加详情页的格式。
标签页:![]()
规则:https://bizhi.ijinshan.com/2/index_{page}.shtml
详情页:![]()
规则:https://bizhi.ijinshan.com/2/{id}.shtml
其中的逻辑基本都是一样的:请求初始页面,提取出详情页面的url,再请求详情页面,解析详情页面拿到图片的链接和地址。
又看了一样代码,好像改两三个地方就直接可以爬了,卧槽…
说干就干,一顿分析之后,改了三个地方,直接就可以爬取别的网站了。
# 定义初始页的url
INDEX_URL = "https://bizhi.ijinshan.com/2/index_{page}.shtml"
# 定义详情页的url
DETAIL_URL = "https://bizhi.ijinshan.com/2/{id}.shtml"
# 定义壁纸的初始url
IMG_URL = 'https://wallpaperm.cmcm.com/{img_url}'
# 定义将要爬取的页数
PAGE_NUMBER = 100
# 此函数的功能是定义详情页的url,并解析详情页,拿到img的url和名字
async def scrape_detail(id):
url = DETAIL_URL.format(id=id)
data = await scrape_api(url)
IMG = re.search('<img src="https://wallpaperm.cmcm.com/(.*?)" alt="(.*?)">',data).group(1)
img_url = IMG_URL.format(img_url=IMG)
name = re.search('<img src="https://wallpaperm.cmcm.com/(.*?)" alt="(.*?)">',data).group(2)
return await scrape_save_img(img_url,name)
ids = re.findall('data-image-id="(.*?)"',index_data,re.S)
之后再次运行,成了!
哇!崔神的代码格式就是不一样,这明明就是一个代码模板啊!
感兴趣的小伙伴可以试一下别的网站。
附上
运行过程
爬取的结果
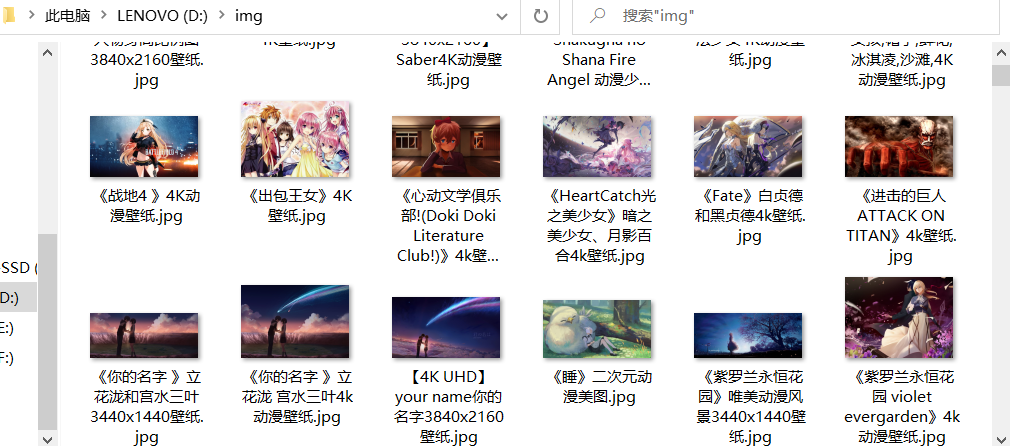
总共爬取了近万张的4K图片,用了不到一个20分钟。
PS:新人第一次发博客,不足的地方多多包涵。